I min stadige jakt på nye prosjekter legge til på den voksende listen av halvferdige ting jeg har prøvd meg på har jeg begynt å kikke på
digital humanities, eller digital humaniora som det sikkert heter på norsk. Mitt utgangspunkt er at jeg har hørt mange historier om hvordan metoder fra matematikk og programmering kan lede til ære, berømmelse og lettvinte publikasjoner når det anvendes på nye områder, så jeg har lest litt rundtomkring og snakket litt med venner av oss med interesser i den retningen, og i løpet av en interessant diskusjon på et cocktailparty nå nylig bestemte jeg meg for at et bra sted å begynne kanskje er å prøve å lage et
XKCD Movie Narrative Chart fra en bok, via et script.
Jeg begynte med å lage et såkalt lexical dispersion plot, som essensielt viser hvor et ord er brukt i en tekst, som viser de mest nevnte personene i
Ringenes Herre. (Merk at jeg har lagt sammen Strider og Aragorn til én person.) Når man har teksten og en liste over personer er dette bortimot en triviell oppgave, men jeg synes likevel det var en morsom ting å gjøre.
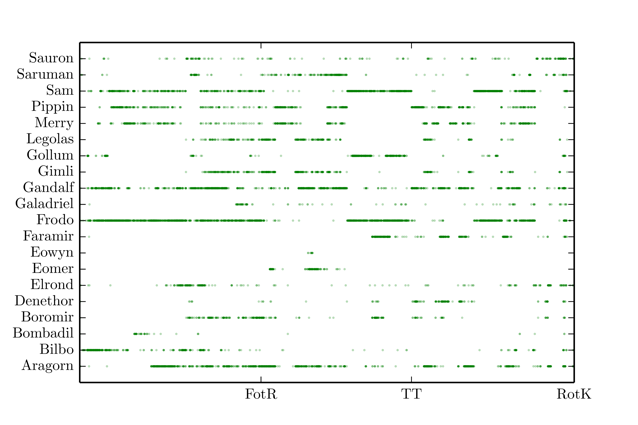
Markeringen på
x-aksen viser slutten på de tre bøkene.
Den store forskjellen på et dispersjonsplott og et XKCD Movie Narrative Chart (heretter kalt XKCD-plott) er at for å lage et XKCD-plott må man finne ut om to personer opptrer i samme scene eller ikke. En første tilnærming er naturligvis å se på de som ofte dukker opp sammen i teksten. En rask inspeksjon av plottet viser at dette ser ut til å kunne være en grei tilnærming, men ikke fullstendig robust. Det er for eksempel en sekvens nær slutten av
Two Towers der Boromir nevnes så ofte at det kan se ut som om han er tilstede, selv om han døde i forrige bok.
Det er mulig man kan håndtere problemet med omtalte personer, for eksempel ved å se på verbene som brukes om dem. En annen tilnærming kunne kanskje være å se bort fra personer som nevnes i tekst som er markert som direkte tale, men det vil ikke nødvendigvis luke ut situasjoner der man
tenker på en person, og vil sikkert ikke være robust i den forstand at det kan anvendes på en vilkårlig bok.
Jeg har uansett tenkt å utsette det problemet, og heller fokusere på å gruppere personer som opptrer sammen i ulike scener. Etter en liten diskusjon med en kollega, og i tråd med idéalet om å få til kule ting med litt lettvint scripting prøvde jeg meg på idéer fra den utrolig kule artikkelen
Using Metadata to Find Paul Revere. Jeg splittet opp teksten i biter på for eskempel 200 ord, og behandlet hver slik bit som en ting man er medlem av hvis man er nevnt i den. Da er det bare en enkel matrisemultiplikasjon som skal til for å finne ut om to biter har mange medlemmer til felles, og jeg tenker at det burde ligge noe der, uten at jeg har kommet så mye videre foreløpig.
Det absolutt kuleste ville være å lage et script som kunne generere et XKCD-plott fullstendig automatisk fra en vilkårlig bok, men det er antagelig så godt som umulig. Kikker man på XKCD-plottet av
Ringenes Herre ser man for eksempel at det viser hvordan Gandalf farter hit og dit i første bok, og det er informasjon man først får tilgang til mye senere når han forklarer hvorfor han ikke dukket opp i Bree. Jeg tror man skal lage en ganske heftig kunstig intelligens for å få til noe slikt. Likevel, det er mange kule delmål på veien dit, så jeg tror jeg sysler videre med dette en stund til.

Comments