I gårsdagens
artikkel om Ajax satte jeg opp en liste over funksjoner jeg kunne tenke meg å implementere med fancy, asynkront javascript. Jeg organiserte listen etter det jeg innbiller meg er stigende vanskelighetsgrad, og helt til slutt førte jeg opp «Google-aktig instantant søk basert på et søketre». Fordi klokka ikke var mer enn rundt midnatt, og fordi det er kjedelig å gjøre lette ting, skrev jeg like godt en implementasjon av et søketre for artikkeldatabasen.
Så hva er egentlig et søketre? Vel, jeg må innrømme at jeg ikke er helt sikker på hvordan det egentlig skal se ut. Det jeg implementerte er basert på det jeg husket fra en samtale med Paul Anton i høst en gang, som igjen var basert på det han husket fra en forelesning for mange år siden, så det er neppe optimalt, men det jeg gjorde var i alle fall følgende:
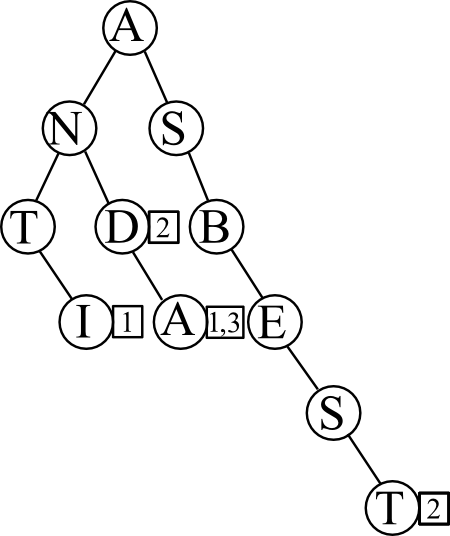
Man bygger opp et tre av noder. Hver node har tre egenskaper: En bokstav, en liste med sub-noder og en liste med artikler. For å bygge opp treet må man så gå gjennom hvert ord i hver artikkel vi har lagret. Man begynner med første bokstav i det ordet, og går til den noden, så går man videre til den sub-noden som tilsvarer neste bokstav i ordet, ogsåvidere, mens man hele tiden oppretter eventuelle manglende noder. Når du kommer til noden som tilsvarer siste bokstav legger du så til artikkelen i den nodens liste over artikler.
Vi tenker oss at vi har de følgende tre, nokså sære, artiklene i databasen:
Artikkel 1: Anda anti
Artikkel 2: Asbest and
Artikkel 3: Anda
Hvis vi bygger opp et søketre basert på disse tre artiklene vil det se slik ut:
Poenget er at nå kan vi søke etter et ord, for eksempel «Anda», ved å begynne på noden som tilsvarer første bokstav, og så går vi videre gjennom treet til vi kommer til noden som tilsvarer siste bokstav, og der har vi en ferdig oppbygget liste over alle artiklene som inneholder det ordet. Når man søker på denne måten er tiden det tar å søke omtrent proporsjonal med lengden på ordet man søker etter, mens når man søker på rå-kraft-måten, altså å sjekke alle ord i alle artikler, er tiden det tar å søke proporsjonal med størrelsen på databasen.
Som jeg nevnte hacket jeg sammen en implementasjon av dette i går kveld, og testing indikerer at det funker latterlig bra, særlig for å være skrevet fritt etter hukommelsen i løpet av en halvtimes tid midt på natten.
Jeg tror imidlertid vi må tenke oss litt om før vi implementerer dette. For det første er det flere problemer med den modellen jeg har brukt her. Den finner for eksempel ikke deler av ord, bare hele ord, og det er greit å ha muligheten til å gjøre begge deler. Dernest har vi problemet at det ikke er noen åpenbar måte å søke etter fraser, siden det kun indekseres etter ord, skjønt akkurat det kan sikkert løses ved å foreta et rå-kraft-søk etter frasen i de artiklene som inneholder alle ordene i frasen, så det er sikkert greit nok.
Det største problemet er imidlertid at man må bygge opp et søketre. Jeg er i ferd med å kjøre en test-indeksering akkurat nå, og det ser ut til at et komplett søketre, som kun indekserer hele ord lengre enn 3 bokstaver, vil ta ca 8 timer å bygge opp, og det vil ta ca 100 MB i databasen. Til sammenligning er databasen vår i dag på omtrent 32 MB. Hvis vi i tillegg skal ha muligheten til å søke etter deler av ord vil størrelsen og tiden øke ytterligere.
Siden jeg ikke er sikker på hvor mye søkefunksjonen egentlig er i bruk, tror jeg kanskje det er best å legge dette prosjektet litt på is. Selv om det er fordømt kult at man nokså lettvint kan lage noe som søker blant rundt en million ord i løpet av noen få hundredeler av et sekund.
-Tor Nordam

Comments