Jobben min består for tiden av å løse massive ligningsystem. Og med massive mener jeg både tette og store. Rett og slett ligninger som tar mange gigabyte å holde i minnet. For å få til dette innen jeg er ferdig med stipendiatperioden og pengene tar slutt er det absolutt essensielt å bruke parallell kode, altså kode som kjører på flere prosessorer samtidig.
Det viser seg imidlertid at det er ikke alltid så enkelt som at det er bare å kaste flere kjerner på et problem, så går det fortere. Vi kjenner naturligvis til
Amdahl og Gustafson, som kommer og tar deg hvis koden din ikke er parallelliserbar. Det er imidlertid ofte slik at kode er ikke enten fullstendig uparallelliserbar eller fullstendig parallelliserbar. Et eksempel på noe som er en mellomting er nettopp det jeg sysler med, altså å løse store ligningsystemer.
Her må jeg nesten digrere litt. I USA har de et prinsipp om at forskning som er finansiert med offentlige midler skal være allment tilgjengelig (bortsett fra hemmelige ting, naturligvis). Takket være at noen i Department of Energy på et eller annet tidspunkt har hatt behov for å løse digre ligningsystemer, finnes det derfor et åpent bibliotek for dette. Det heter
Scalapack, og fremstår for meg nesten som svart magi, både fordi det er skrevet i Fortran 77 og fordi jeg ikke aner hvordan det funker, men funker gjør det.
Jeg aner ikke hvordan det foregår, men Scalapack løser ligningsystemer i parallell. For at det skal funke må imidlertid de forskjellige prosessorene snakke litt sammen av og til, og jo flere prosessorer du bruker, jo mer må de snakke sammen. Det er derfor gjerne slik at ved å doble antall prosessorer kan du kutte ned på veggtiden*, men du halverer den ikke. Det betyr at hvis du har dårlig tid, og ikke betaler for kjernetimene** dine selv, kan dette lønne seg, men det er altså en vurderingssak.
Hvor mye det koster å kommunisere mer kommer an på maskninen du sitter på. Til daglig bruker jeg en maskin som heter Kongull, som har 1200 kjerner, men den er ikke en superdatamaskin i ordets rette forstand, fordi den består bare av 100 maskiner med 12 kjerner hver som er koblet sammen med 10Gb-nettverk. Det betyr at straks du trenger å kommunisere mellom to maskiner må du ut på nettverket, og da går ting straks mye tregere. Jeg antar man kan argumentere for at Kongull er et eksempel på en Beowulf-klynge.
HECToR, som jeg også kjører på, er derimot en ekte superdatamaskin, fordi maskinene den består av er koblet sammen med det latterlig raske Gemini Interconnect fra Cray.
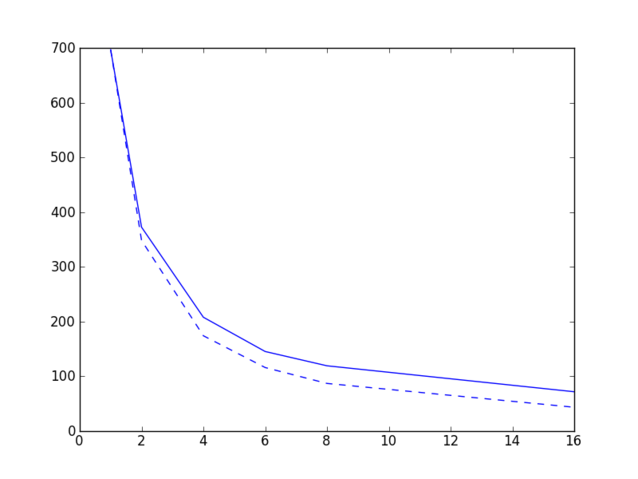
Jeg gjorde noen tester på Kongull i dag, der jeg løste et ligningsystem på 12 gigabytes på 1, 2, 4, 6, 8 og 16 noder, der hver node har 12 kjerner, og her er resultatene.
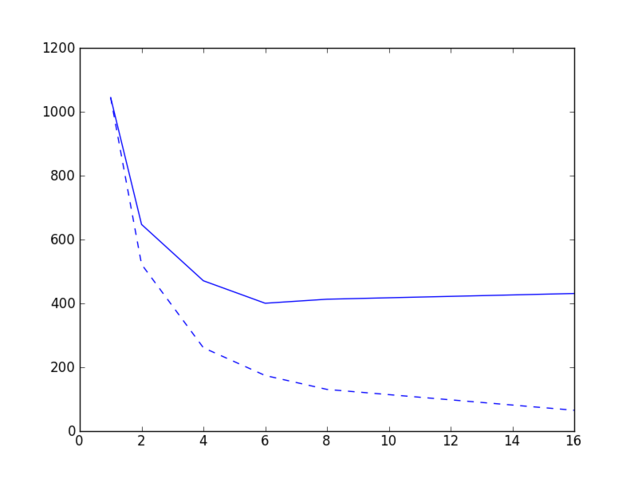 Heltrukket linje viser faktisk veggtid som funskjon av antall noder, stiplet linje viser teoretisk veggtid ved perfekt parallellisering.
Heltrukket linje viser faktisk veggtid som funskjon av antall noder, stiplet linje viser teoretisk veggtid ved perfekt parallellisering.Jeg tenkte å kjøre den samme testen på HECToR, men det tar litt tid, fordi man må stå en stund i kø for å få kjøre selv en ganske kort jobb på flere noder. Resultater kommer antagelig senere. Uansett, dagens moral er at det er ikke bare å kjøre på med flest mulig kjerner, selv ikke om du har det travelt og ikke betaler for regnetiden. Som vi ser av grafen øker faktisk veggtiden når vi går fra 8 til 16 noder, fordi den tiden man tjener på at man har flere prosessorer til å jobbe blir mer enn oppveid av tiden man taper på ekstra kommunikasjon. Sett slikt.
-Tor Nordam
* Veggtid er den tiden klokken på veggen sier at det tar å kjøre jobben din.
** Kjernetiden er veggtiden ganger antall kjerner. Det er denne man betaler for.

Comments